—
title: “Synthetic Data Feedback Loop: Will AI Hit a Data Ceiling in 2027?”
slug: synthetic-data-feedback-loop-ai-data-ceiling-2027-en
category: insights
language: en
focus_keyword: synthetic data feedback loop
seo_title: “Synthetic Data Feedback Loop: AI’s Data Ceiling Reality Check (2027)”
seo_description: “Model collapse, data exhaustion, and the synthetic data feedback loop—will AI hit a wall in 2027? Analysis of multimodal expansion, RLHF, agent data, and real risks ahead.”
rewritten_from_cn_id: 1144
—
In 2024, Epoch AI published a forecast that rattled the industry: high-quality public text data would run out between 2026 and 2032. That same July, Nature featured Shumailov et al.’s paper with a visually striking demonstration—when models recursively train on their own generated output, quality collapses into noise within a few generations. They called it “model collapse.” Put these together, and you get a seductive narrative: the internet is running dry, AI training on synthetic data poisons itself, so scaling laws will hit a wall around 2027.
I don’t buy it. The story conflates “data scarcity” with “model collapse”—a category error. Short term, synthetic data is essential; every frontier lab uses it, and you can’t build GPT-4-level models without it. Long term, pure recursive synthetic training is toxic, but no one does that. What determines 2027 isn’t “how many tokens are left” but progress on four fronts: data diversity, feedback mechanisms, multimodal expansion, and agent interaction data. Let’s break it down.
Synthetic Data: From Stopgap to Default
Synthetic data isn’t new. AlphaGo Zero proved in 2017 that self-play data alone can surpass human-level play. The inflection point was 2023-2024, when labs migrated this approach from games to language.
Anthropic’s Constitutional AI replaces much of human feedback with model-generated feedback guided by a “constitution”—essentially scaling synthetic preference data. OpenAI increasingly relies on distillation: strong models generate high-quality reasoning chains to train smaller models; the o1 series depends on this loop. Google DeepMind uses code execution traces and math solutions as synthetic supervision signals in Gemini training. Meta’s Llama 3 technical report openly states that a significant portion of post-training data is model-generated and filtered. Microsoft’s Phi series goes further—its entire pitch is “textbook-quality synthetic data.”
Current reality: synthetic data is no longer plan B. It’s the default. Debating “whether to use it” is outdated. The question is “how to use it, and where does it break?”
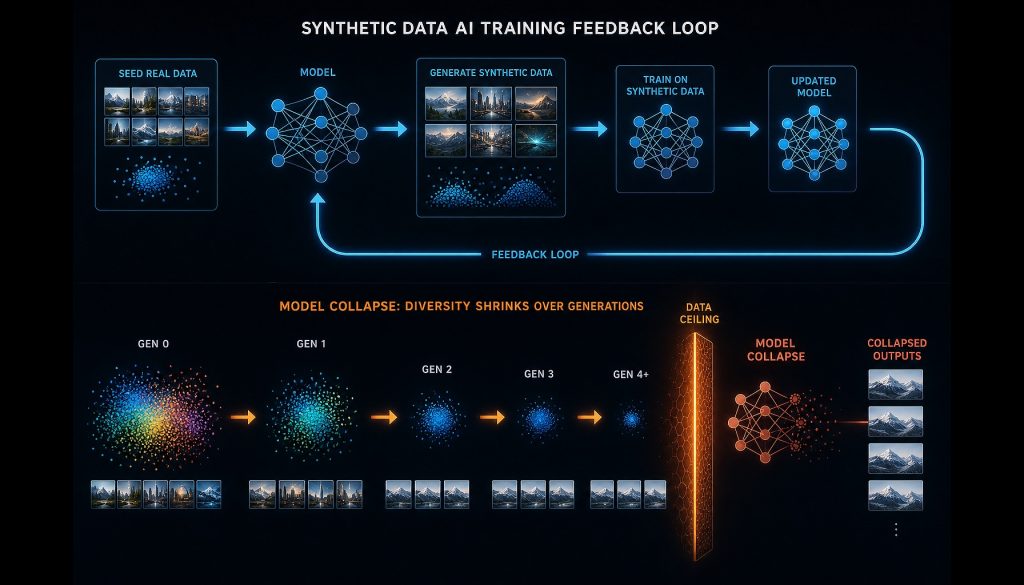
What the Model Collapse Paper Says—and Doesn’t Say
Nature’s model collapse paper tested a specific scenario: each generation trains almost entirely on the previous generation’s output, replacing original data, then recursively trains again. Under pure recursion, distribution tails flatten fast, variance shrinks, and small language models degrade into nonsense within a few iterations. The visuals are compelling—they show AI “eating its own output and getting sick.”
But the experiment rests on assumptions often overlooked. First, it assumes synthetic data comprises nearly 100% of training data, with original data discarded. Second, models are relatively small, and iteration depth is high. Third, there’s no filtering, weighting, or mixing strategy—just “throw it in and train.”
Follow-up work quickly pushed back. Gerstgrasser et al.’s 2024 paper “Is Model Collapse Inevitable?” used more realistic settings: as long as each generation mixes original real data with synthetic data, collapse doesn’t happen—models improve steadily. Feng et al. showed that selective filtering pipelines prevent variance collapse. CMU and Stanford replications reached similar conclusions: collapse is the product of an extreme “full replacement” assumption, not an inherent property of synthetic data.
In other words, model collapse is a real mathematical phenomenon describing a training regime no one would execute. No frontier lab discards real data to train purely on synthetic recursion. It’s like asking “what happens if you only eat your own vomit?”—the answer is death, but it’s not anyone’s diet plan.
Why 2027 Won’t Hit a Data Ceiling
Shift focus from “total text token count,” and you’ll see four forces redefining what “training data” means.
One: Multimodal Opens a 100x Larger Reservoir
Text was AI’s earliest meal because it’s easiest to scrape. But text is the tip of the iceberg. YouTube adds hundreds of hours of video per minute. Global cameras produce exabyte-scale video streams daily. Add audio, 3D scans, robotics sensors, autonomous vehicle fleets, satellite imagery—conservatively, this data pool is 100x larger than public text, and the industry has barely started systematically using it.
Post-Sora video models prove a point: physical consistency across frames, temporal causality, spatial structure—this “world knowledge” comes largely from video, not text descriptions. Gemini 1.5 processing multi-hour videos in million-token contexts, DeepMind’s RT-X and Genie treating robot trajectories as training data—all point the same direction. When models learn physics, space, and social dynamics directly from video and embodied interaction, “running out of text” matters far less.
Two: RLHF and RLAIF Turn Data Problems into Feedback Problems
Pre-training needs massive data, but capability gains increasingly come from post-training, which consumes feedback not tokens. OpenAI’s o1 and follow-on reasoning models prove that given a verifiable environment (math problems, code execution, formal proofs), models can push reasoning capability high through reinforcement learning on relatively small datasets. The bottleneck isn’t “how much new text” but “how many verifiable tasks and high-quality preference signals.”
RLAIF further replaces human feedback with model feedback. This sounds circular, but in domains with clear ground truth or executable verification (code, math, tool use), model self-scoring is viable and efficient. This reframes “we’re running out of data” into “can we build more environments with verification signals?”—an entirely different bottleneck.
Three: Agent Interaction Data Is a New High-Value Corpus
As Claude, ChatGPT, Cursor, Devin scale, they generate a new data class daily: complete task flows, tool call sequences, error and recovery trajectories, human mid-course corrections. This data barely exists on the public internet because it’s “traces of action” not “finished text.”
Its value lies in density. A typical webpage may have a few useful tokens, while an agent trace with tool calls, failed retries, and eventual success is information-dense for training “how to do things” models. Anthropic and OpenAI systematically filter this data from user interactions for downstream training (within their privacy commitments). As agents scale, high-quality interaction corpus grows exponentially, not shrinks.
Four: The Bottleneck Was Never Token Count—It’s Diversity, Verification, Long Tail
Post-Chinchilla, the industry knows model scale and data scale must match proportionally, but few discuss how to measure “data quality.” Empirically, 1 TB of high-quality, diverse, verified data outweighs 10 TB scraped from the internet’s garbage pile. Phi series training on tens of billions of curated synthetic tokens to match larger models already proves this.
What truly limits 2027 model capability isn’t “how many tokens remain” but: can we build data covering enough domains, languages, and cultures? Enough coverage on long-tail tasks (rare diseases, low-resource languages, specialized fields, edge cases)? Verification or quality signals for every training sample? This is an engineering problem, not a ceiling.
Real Risks to Watch—They’re More Subtle
Rejecting the 2027 wall narrative doesn’t mean smooth sailing. Synthetic data’s real risks are more insidious.
First: model homogenization. When everyone distills GPT-4-level strong models and uses their output as synthetic data, the entire industry’s model distribution converges toward the same prior. Many open-source models are essentially “GPT-4 shadows.” This reduces ecosystem diversity, long-term weakening collective progress.
Second: long-tail knowledge erosion. Synthetic data samples from known distributions. High-frequency knowledge gets reinforced; low-frequency knowledge slowly vanishes. Each round of “model A generates data to train model B” shaves off a bit of the tail. It won’t cause immediate collapse, but over a decade, rare but important internet knowledge may disappear from mainstream models.
Third: cultural bias amplification. Synthetic data generators carry biases. Data they produce encodes these biases into the next generation, amplifying further each round. English-centrism, Western-centrism, mainstream-culture-centrism intensify through synthetic loops. Low-resource languages and minority cultures become more marginalized.
Fourth: open dataset contamination. Common Crawl, RedPajama, public corpora now unavoidably mix in large amounts of AI-generated content. Since 2024, “washing synthetic data out” of open datasets has become an industrial challenge. This isn’t model collapse, but it makes “training on authentic human data” an irreversible luxury. Internet text born after 2024 may be less valuable for training than pre-2024 text.
These risks lack the drama of “2027 wall,” but they’re more real and harder to reverse.
Counterarguments and Responses
Counterargument 1: You underestimate model collapse; frontier labs can’t avoid it.
Response: Labs have resources ordinary researchers lack—massive quality-scored real data, strict synthetic data filtering pipelines, traceability for every data source. Anthropic’s publicly shared pipeline details show synthetic data undergoes multi-layer filtering and mixing strategies before training. Collapse is the product of “throw-it-in-and-train,” not industrial-grade pipelines.
Counterargument 2: However much multimodal data exists, core “reasoning ability” still comes from text. If text runs out, it’s over.
Response: This view is too narrow on reasoning’s source. Recent progress shows reasoning increasingly comes from post-training reinforcement learning, not pre-training token counts. o1, DeepSeek-R1, Gemini 2 reasoning improvements rely on verified environments and feedback loops, not scraping more text.
Counterargument 3: High-quality data is scarce. No amount of synthetic data compensates.
Response: Partly true. “Gold standard” data like Wikipedia, textbooks, top-tier journals are scarce. But using strong models to “extend” these gold standards into more variants (paraphrasing, translation, follow-ups, counterexamples) turns scarce assets into scalable ones—provided you acknowledge extended data as derivatives, not new originals. Phi’s path proves it works.
Counterargument 4: Diversity and long-tail coverage ultimately need new data. Where does new data come from?
Response: Two new sources. One: agent interaction-generated trajectories (this data class barely existed pre-2023). Two: “long-tail private domains” like scientific experiments, robot collection, enterprise proprietary data. The latter’s volume is enormous; it sat idle because there was no commercial path. Now AI labs are rapidly partnering with industries for data collaboration.
Advice for Developers and Enterprises
For teams training models or heavily using AI:
Use synthetic data as leverage, not staple food. In mixing strategies, keep real data above a floor—empirically, retaining 30%+ original data significantly reduces distribution collapse risk.
Build traceability and quality scoring pipelines for synthetic data. Track which model, which generation, which prompt generated each sample. When things break, you can slice and diagnose.
If you’re training domain models, private data is your moat. Public internet data’s marginal value is rapidly declining. Your customer service logs, internal docs, operation logs, domain-specific data—these are what competitors can’t replicate.
Beware “distilling GPT-4” as a long-term path. Short-term, it’s a quick start. Long-term, your model becomes someone else’s shadow. At minimum, introduce proprietary feedback and verification environments in post-training.
If you’re doing evals, post-2025 public benchmarks are increasingly contaminated by training data. Private holdout test sets are mandatory.
FAQ
Q1: Will synthetic data cause collective AI stagnation in 2027?
No. Stagnation requires four simultaneous failures: multimodal expansion fails, RLHF/RLAIF plateaus, agent interaction data unavailable, private data uncommercializable. The probability of all four failing together is very low.
Q2: Is the Nature model collapse paper overhyped?
The paper itself is rigorous math. Its dissemination got simplified. It proves “under pure recursive no-filter extreme assumptions, collapse inevitably occurs,” not “using synthetic data for training causes collapse.” These two conclusions are worlds apart.
Q3: Will ordinary developers using synthetic data to fine-tune small models face collapse?
Controllable. Mix real data, set quality filters, limit recursive generations (don’t fine-tune on your own last fine-tune’s output), and you avoid the collapse zone. A few generations with mixed training are safe.
Q4: Common Crawl is already contaminated by AI content. What now?
Long-term, “pre-2024 snapshots” will become rare high-purity real data resources. Meanwhile, the industry will develop better synthetic content detection and filtering tools. But a fully clean public internet corpus may never return.
Q5: Which directions are worth long-term bets?
Verified signal RL environments, agent interaction data infrastructure, multimodal especially video and embodied data, private data partnerships, synthetic data quality assessment tools. These five will be hot 2026-2028.
Conclusion
“AI training on AI data hits a wall” is a high-transmission, low-precision story. Reality: synthetic data is already default, model collapse is an extreme-assumption artifact not engineering reality, 2027’s bottleneck won’t appear in total token count. Multimodal, RLHF/RLAIF, agent interaction data—these three forces combined sustain three to five more years of model capability expansion.
But this doesn’t mean complacency. Model homogenization, long-tail erosion, bias amplification, open dataset contamination—these are synthetic data era’s real chronic diseases. They won’t cause sudden collapse in any given year, but over a decade they make the entire ecosystem narrower, more homogenous, more fragile. That’s the choice worth making.
If I must give one verdict: 2027 won’t see a data ceiling, but we’ll see ever more clearly that what determines how far AI goes was never how much data exists, but where data comes from, who verifies it, and whose world it covers.
Stay updated with our latest AI insights


