一个数据工程师盯着屏幕上的错误日志,第三次手动重启失败的 ETL 任务。”为什么第 47 步又卡住了?”他问旁边的同事。”上次是第 23 步,这次换了个地方挂。”同事头也不抬:”因为我们没有工作流编排,全靠脚本串联。”
这是 2020 年代初很多数据团队的日常。任务失败了不知道从哪重跑,状态散落在各处日志里,一个环节出问题整条流水线停摆。工作流编排工具的出现,就是为了解决这类问题:把复杂的多步骤任务管理起来,自动重试、状态追踪、依赖管理、错误恢复。
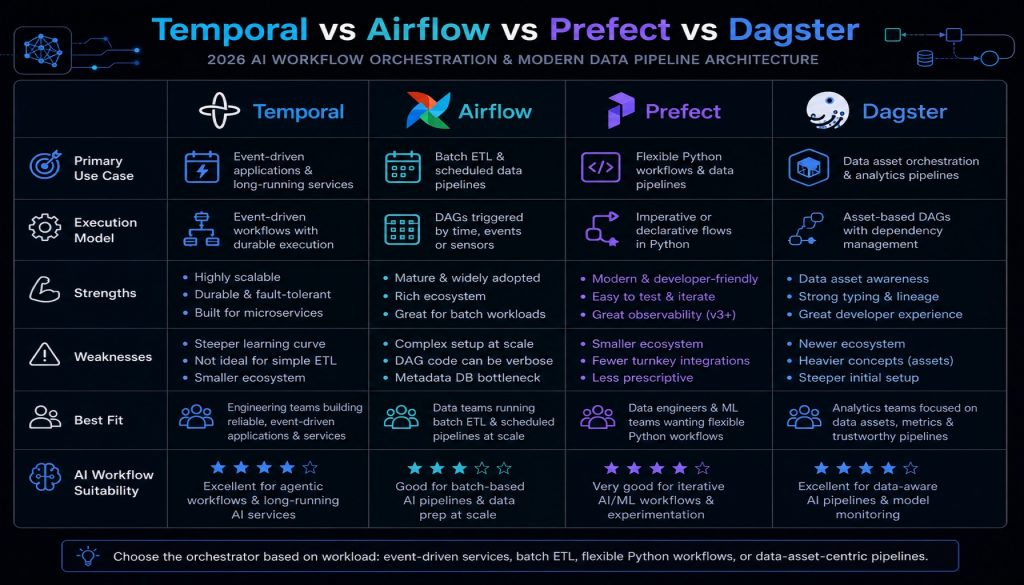
到了 2026 年,这个领域已经有了明确的分化。Apache Airflow 是老牌数据管道调度工具,Python DAG 写法几乎成了行业标准。Prefect 和 Dagster 是新一代数据流编排工具,对标 Airflow 但开发体验更好。Temporal 则走了完全不同的路线,它不是”数据管道工具”,而是通用的分布式工作流引擎,适用于任何需要可靠执行的长时间运行流程。
这四个工具经常被放在一起比较,但它们其实解决的是不同层面的问题。选错了工具,要么是杀鸡用牛刀,要么是拿着水果刀去砍树。这篇文章会从定位、编程模型、状态管理、适用场景四个维度拆解,帮你找到真正适合团队的那个。
Temporal:通用工作流引擎,不只是数据管道
Temporal 的创始团队来自 Uber 的 Cadence 项目。他们要解决的问题不是”调度数据任务”,而是”如何让分布式系统里的复杂流程可靠执行”。订单支付流程、用户注册流程、跨服务的审批流程——这些都是 Temporal 的目标场景。
核心理念:Durable Execution
Temporal 最独特的地方是 durable execution(持久化执行)。你写的工作流代码看起来像普通的函数调用,但执行过程中的每一步状态都会被持久化。进程崩溃了?重启后从上次执行的位置继续。某个 API 调用超时了?自动重试。依赖的服务挂了?等它恢复再继续。
这种”写起来像同步代码,运行起来像分布式系统”的体验,是 Temporal 的核心卖点。你不需要自己管理状态机、不需要写复杂的错误恢复逻辑,Temporal 的执行引擎会处理所有这些。
编程模型
Temporal 的工作流用普通编程语言写(Go、Java、Python、TypeScript、.NET),不需要特殊的 DSL。一个工作流就是一个函数,里面可以调用 Activity(实际执行任务的单元)、启动子工作流、等待外部信号。
“`python
@workflow.defn
class OrderWorkflow:
@workflow.run
async def run(self, order_id: str) -> str:
# 步骤 1:验证库存
await workflow.execute_activity(
check_inventory,
order_id,
start_to_close_timeout=timedelta(seconds=30),
)
# 步骤 2:扣款
payment_result = await workflow.execute_activity(
charge_payment,
order_id,
start_to_close_timeout=timedelta(minutes=5),
)
# 步骤 3:发货
await workflow.execute_activity(
ship_order,
order_id,
start_to_close_timeout=timedelta(hours=1),
)
return “Order completed”
“`
这段代码看起来就是顺序执行三个步骤,但 Temporal 保证:任何一步失败了会自动重试,进程重启不影响执行,每步的超时独立管理。你不需要写任何状态管理代码。
适用场景
Temporal 最适合”长时间运行、有复杂状态、需要高可靠性”的业务流程。典型例子:
- 订单履约流程(下单 → 支付 → 发货 → 配送 → 签收,每步可能间隔几小时到几天)
- 用户入职流程(提交申请 → 审批 → 背景调查 → 合同签署,有人工审批环节)
- 跨系统数据同步(从 A 系统读数据 → 转换 → 写入 B 系统 → 验证一致性)
- 微服务编排(Saga 模式的分布式事务,需要补偿机制)
不适合的场景:纯批处理数据任务、定时任务、简单的 cron job。Temporal 的强项是”复杂状态 + 长时间运行”,如果你的任务就是”每天凌晨跑个 SQL 导出数据”,用 Temporal 就是杀鸡用牛刀了。
定价和部署
Temporal 有开源版(MIT 协议)和托管云服务(Temporal Cloud)。开源版需要自己部署 Temporal Server(依赖 Cassandra/PostgreSQL + Elasticsearch),适合有运维能力的团队。Temporal Cloud 按执行的 Action 数量计费,免费层每月 100 万 Actions,付费从 $200/月起步。
Apache Airflow:数据管道调度的事实标准
Airflow 2010 年在 Airbnb 诞生,2016 年成为 Apache 顶级项目。到 2026 年,它依然是数据工程领域最广泛使用的调度工具。你在招聘 JD 里看到”熟悉 Airflow”的频率,远高于其他三个工具。
核心理念:DAG 即任务依赖图
Airflow 的核心概念是 DAG(Directed Acyclic Graph,有向无环图)。你定义一组任务和它们之间的依赖关系,Airflow 负责按依赖顺序调度执行。任务 A 完成后才执行任务 B,任务 C 和 D 可以并行,任务 E 等待 C 和 D 都完成。
这种”显式声明依赖关系”的设计,非常适合数据管道:先从数据库抽取数据,再做清洗转换,最后加载到数据仓库。每一步都是独立的任务,依赖关系清晰。
编程模型
Airflow 的 DAG 用 Python 定义,但它的执行模型和普通 Python 程序不同。DAG 文件会被 Airflow 反复解析(每分钟一次),所以不能在 DAG 文件里做重计算。实际的任务逻辑写在 Operator 里。
“`python
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime, timedelta
def extract_data():
# 从数据库提取数据
pass
def transform_data():
# 数据清洗转换
pass
def load_data():
# 加载到数据仓库
pass
with DAG(
‘etl_pipeline’,
start_date=datetime(2026, 1, 1),
schedule_interval=’@daily’,
catchup=False,
) as dag:
extract = PythonOperator(
task_id=’extract’,
python_callable=extract_data,
)
transform = PythonOperator(
task_id=’transform’,
python_callable=transform_data,
)
load = PythonOperator(
task_id=’load’,
python_callable=load_data,
)
extract >> transform >> load # 定义依赖关系
“`
这个 DAG 定义了三个任务的执行顺序。>> 操作符表示依赖关系,extract 完成后执行 transform,transform 完成后执行 load。
适用场景
Airflow 最适合定时批处理数据任务。典型场景:
- ETL/ELT 数据管道(每天从业务数据库同步到数据仓库)
- 数据质量检查(每小时跑一次数据验证)
- 报表生成(每周生成业务报表)
- 机器学习训练流水线(数据准备 → 特征工程 → 模型训练 → 模型评估)
不适合的场景:实时流处理(Airflow 不是流处理引擎)、需要亚秒级调度的任务、长时间运行的业务流程(Airflow 的任务设计假设是”跑完就结束”)。
定价和部署
Airflow 是开源免费的(Apache 2.0 协议)。你可以自己部署(需要 PostgreSQL/MySQL + Redis/RabbitMQ + Celery/Kubernetes Executor),也可以用托管服务。托管选项包括:
- AWS MWAA(Amazon Managed Workflows for Apache Airflow):$0.49/小时起
- Google Cloud Composer:$0.074/vCPU/小时起
- Astronomer:$100/月起(托管 Airflow + 企业支持)
Prefect:现代化的数据流编排
Prefect 的创始团队觉得 Airflow 的设计太老了:DAG 文件被反复解析、任务失败后重跑整个 DAG、UI 不够现代。他们在 2018 年创办 Prefect,目标是”做一个更好的 Airflow”。
核心理念:Negative Engineering
Prefect 的设计哲学叫”negative engineering”:不强加限制,让用户用熟悉的方式写代码。你不需要学习特殊的 DSL,不需要理解 Airflow 的 DAG 解析机制,就写普通的 Python 函数,用 @flow 和 @task 装饰器标记一下就行。
编程模型
Prefect 的 Flow 和 Task 就是普通 Python 函数。你可以用 if/else、for 循环、try/except,写起来和普通脚本没区别。
“`python
from prefect import flow, task
@task
def extract_data():
# 提取数据
return data
@task
def transform_data(data):
# 转换数据
return transformed
@task
def load_data(data):
# 加载数据
pass
@flow
def etl_pipeline():
data = extract_data()
transformed = transform_data(data)
load_data(transformed)
if __name__ == “__main__”:
etl_pipeline()
“`
这段代码既可以直接运行(python etl.py),也可以部署到 Prefect Server 定时调度。不需要特殊的 DAG 解析,不需要理解执行上下文。
适用场景
Prefect 的定位和 Airflow 很接近,但更适合:
- 需要动态生成任务的场景(任务数量不固定,取决于运行时数据)
- 开发迭代频繁的团队(Prefect 的本地开发体验比 Airflow 好)
- 重视可观测性的团队(Prefect Cloud 的 UI 和监控比 Airflow 现代很多)
- Python 为主的数据团队(Prefect 的 Python API 更自然)
不适合的场景:和 Airflow 类似,不适合实时流处理和长时间运行的业务流程。
定价和部署
Prefect 2.0 开源(Apache 2.0),可以自托管 Prefect Server。Prefect Cloud 是托管版,有免费层(每月 20,000 Task Runs),付费从 $250/月起(Starter Plan),按 Task Run 数量计费。
Dagster:以数据为中心的编排工具
Dagster 2019 年开源,创始人之前在 Facebook 和 Palantir 做数据基础设施。他们的观点是:现有的编排工具都是”以任务为中心”的,但数据工程应该”以数据为中心”。任务是手段,数据才是目的。
核心理念:Software-Defined Assets
Dagster 的核心概念是 Asset(资产)。一个 Asset 可以是一张数据表、一个文件、一个 ML 模型。你定义”如何生成这个 Asset”,Dagster 负责追踪 Asset 之间的依赖关系、数据血缘、更新时间。
这种”声明式”的设计,让你关注”我需要什么数据”而不是”我要执行什么任务”。Dagster 会自动推导出执行顺序。
编程模型
Dagster 的 Asset 定义用 @asset 装饰器。函数返回值就是 Asset 的内容,函数参数声明依赖的上游 Asset。
“`python
from dagster import asset
@asset
def raw_orders():
# 从数据库读取原始订单数据
return pd.read_sql(“SELECT * FROM orders”, conn)
@asset
def clean_orders(raw_orders):
# 清洗数据,依赖 raw_orders
return raw_orders.dropna()
@asset
def order_metrics(clean_orders):
# 计算指标,依赖 clean_orders
return clean_orders.groupby(‘date’).agg({‘amount’: ‘sum’})
“`
这三个 Asset 形成了依赖链:raw_orders → clean_orders → order_metrics。Dagster 会自动按顺序执行,并追踪每个 Asset 的更新时间和数据血缘。
适用场景
Dagster 最适合”数据密集型”的场景,特别是:
- 数据仓库建模(DBT + Dagster 是常见组合)
- 特征工程管道(ML 训练依赖的特征表)
- 数据产品开发(BI 报表、数据 API 依赖的数据表)
- 需要数据血缘追踪的组织(合规、审计、影响分析)
不适合的场景:通用的业务流程编排(Dagster 的设计假设是”生成数据资产”,不适合订单流程、审批流程这类场景)。
定价和部署
Dagster 开源(Apache 2.0)。可以自托管 Dagster Daemon + Dagit UI。Dagster Cloud 是托管版,有免费层(单用户、有限资源),付费从 $399/月起(Pro Plan),按 Compute Credits 计费。
对比维度:谁更适合你?
1. 核心定位
- Temporal:通用工作流引擎,适合业务流程编排
- Airflow:数据管道调度工具,适合批处理 ETL
- Prefect:现代化的数据流编排,Airflow 的改进版
- Dagster:以数据为中心的编排,强调数据血缘和可观测性
2. 编程模型
- Temporal:普通函数调用,状态自动管理
- Airflow:DAG + Operator,声明式依赖
- Prefect:普通 Python 函数 + 装饰器
- Dagster:Asset 依赖图,声明式数据血缘
3. 状态管理
- Temporal:Durable execution,状态自动持久化,进程重启不影响执行
- Airflow:任务状态存数据库,失败后需要手动或自动重跑整个任务
- Prefect:任务状态存 Prefect Server,支持部分重跑
- Dagster:Asset 状态和数据血缘统一管理,支持增量更新
4. 适用场景
| 场景 | Temporal | Airflow | Prefect | Dagster |
|---|---|---|---|---|
| 订单履约流程 | ✅ 最适合 | ❌ 不适合 | ❌ 不适合 | ❌ 不适合 |
| 批处理 ETL | ⚠️ 可以但杀鸡用牛刀 | ✅ 最适合 | ✅ 最适合 | ✅ 适合 |
| 实时数据管道 | ⚠️ 不是为此设计 | ❌ 不支持 | ❌ 不支持 | ⚠️ 可以但不是最佳 |
| ML 训练管道 | ⚠️ 可以 | ✅ 适合 | ✅ 适合 | ✅ 很适合 |
| 数据仓库建模 | ❌ 不适合 | ✅ 适合 | ✅ 适合 | ✅ 最适合 |
| 微服务编排 | ✅ 最适合 | ❌ 不适合 | ❌ 不适合 | ❌ 不适合 |
5. 学习曲线
- Temporal:中等。核心概念不多,但要理解 durable execution 的执行模型
- Airflow:陡峭。DAG 解析机制、执行上下文、XCom、各种 Executor 的差异
- Prefect:平缓。如果你会 Python,基本没有额外学习成本
- Dagster:中等。Asset 和数据血缘的概念需要理解,但设计很直观
6. 运维复杂度
- Temporal:高。需要部署 Temporal Server、Cassandra/PostgreSQL、Elasticsearch
- Airflow:高。需要部署 Webserver、Scheduler、Executor、数据库、消息队列
- Prefect:中。需要部署 Prefect Server/Orion + PostgreSQL,比 Airflow 简单
- Dagster:中。需要部署 Dagster Daemon + Dagit + PostgreSQL
选型建议:按场景匹配工具
你在做数据工程,每天跑 ETL 任务
首选 Airflow 或 Prefect。Airflow 是行业标准,生态成熟,招人容易。Prefect 是现代化的选择,开发体验更好,UI 更友好。如果团队在 2026 年刚起步,推荐 Prefect。如果已经有 Airflow 经验,继续用 Airflow 没问题。
不推荐 Temporal(杀鸡用牛刀)和 Dagster(学习曲线更陡)。
你在建数据仓库,需要追踪数据血缘
首选 Dagster。它的 Asset 模型天然适合数据仓库场景。和 DBT 配合使用,可以统一管理数据转换和数据血缘。
次选 Airflow + 外部数据血缘工具(如 OpenLineage)。Prefect 在数据血缘方面不如 Dagster 原生。
你在做业务流程编排,有复杂状态和长时间运行
只推荐 Temporal。订单履约、用户入职、跨系统审批这类场景,Temporal 的 durable execution 是唯一合适的选择。其他三个工具都不是为此设计的。
你在做 ML 训练管道
Airflow、Prefect、Dagster 都适合。选哪个取决于你的其他需求:
- 如果团队已经在用 Airflow,继续用
- 如果重视开发体验,选 Prefect
- 如果需要特征表管理和血缘追踪,选 Dagster
Temporal 不适合,因为 ML 训练通常是批处理任务,不需要 durable execution。
你在做微服务编排,需要 Saga 模式
只推荐 Temporal。分布式事务、补偿机制、跨服务编排,Temporal 是为此设计的。其他三个工具都不适合。
最后的思考
工作流编排工具的选择,本质上是在回答”我要解决什么问题”。Temporal 解决的是”复杂业务流程的可靠执行”,Airflow/Prefect 解决的是”数据任务的定时调度”,Dagster 解决的是”数据血缘和可观测性”。
2026 年的趋势是:这些工具的边界越来越清晰。Temporal 不会去抢 Airflow 的数据工程市场,Dagster 也不会去做通用的业务流程编排。选对了工具,开发效率翻倍;选错了工具,天天跟框架较劲。
如果你还不确定,建议先问自己三个问题:
- 我的任务是定时批处理,还是长时间运行的流程?
- 我需要数据血缘追踪吗?
- 我的团队有多少运维能力?
答案会指向正确的选择。
Stay updated with our latest AI insights