A data engineer stares at error logs, manually restarting a failed ETL job for the third time. Step 47 crashed this run. Last time it was step 23. The root cause? No workflow orchestration. Just scripts chained together with duct tape and hope.
That scenario was painfully common in the early 2020s. Workflow orchestration tools exist to solve it: managing multi-step processes with automatic retries, state tracking, dependency resolution, and failure recovery.
By 2026, the field has split into distinct categories. Apache Airflow remains the de facto standard for data pipeline scheduling. Prefect and Dagster represent the next generation, targeting better developer experience while staying in the data orchestration lane. Temporal takes a fundamentally different approach as a general-purpose distributed workflow engine built for any long-running, stateful process.
These four tools get compared constantly, but they solve problems at different layers of the stack. Pick the wrong one and you’re either swatting flies with a sledgehammer or bringing a pocket knife to fell a tree. This article breaks down positioning, programming model, state management, and use cases to help you match the right tool to your team’s actual needs.
Temporal: A General-Purpose Workflow Engine
Temporal’s founding team came from Uber’s Cadence project. Their goal was never “schedule data jobs.” They set out to answer a harder question: how do you make complex processes execute reliably across distributed systems? Payment flows, user onboarding sequences, cross-service approval chains: these are Temporal’s home turf.
Durable Execution as the Core Primitive
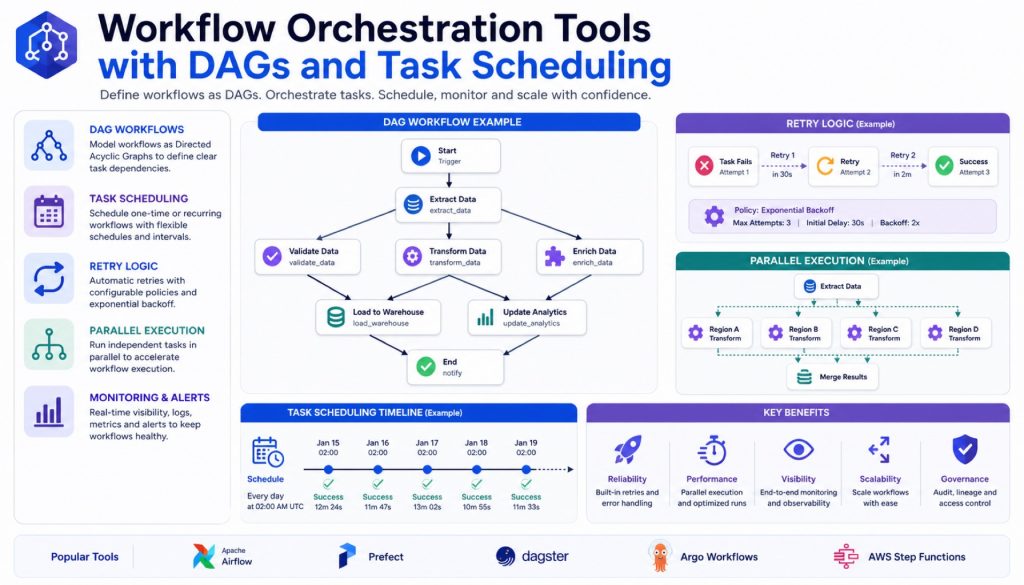
Temporal’s differentiator is durable execution. Your workflow code reads like ordinary function calls, but every step’s state gets persisted automatically. Process crashes? It resumes from where it left off after restart. An API call times out? Automatic retry. A downstream service goes down? The workflow waits and continues when it recovers.
You write code that looks synchronous while the runtime handles distributed systems complexity behind the scenes. No hand-rolled state machines. No manual recovery logic. The execution engine takes care of all of that.
Programming Model
Temporal workflows are written in standard programming languages (Go, Java, Python, TypeScript, .NET) with no special DSL required. A workflow is a function that calls Activities (the units that do actual work), spawns child workflows, or waits for external signals.
“`python
@workflow.defn
class OrderWorkflow:
@workflow.run
async def run(self, order_id: str) -> str:
# Step 1: Verify inventory
await workflow.execute_activity(
check_inventory,
order_id,
start_to_close_timeout=timedelta(seconds=30),
)
# Step 2: Charge payment
payment_result = await workflow.execute_activity(
charge_payment,
order_id,
start_to_close_timeout=timedelta(minutes=5),
)
# Step 3: Ship order
await workflow.execute_activity(
ship_order,
order_id,
start_to_close_timeout=timedelta(hours=1),
)
return “Order completed”
“`
This code looks like sequential execution of three steps. Temporal guarantees that any failed step retries automatically, process restarts don’t interrupt execution, and each step’s timeout is managed independently. You write zero state management code.
Where Temporal Fits
Temporal excels at long-running processes with complex state and high reliability requirements:
- Order fulfillment (order placed, payment charged, shipped, delivered, confirmed, with hours or days between steps)
- Employee onboarding (application submitted, approval, background check, contract signing, with human-in-the-loop steps)
- Cross-system data synchronization with consistency verification
- Microservice orchestration using the Saga pattern with compensation logic
Where it doesn’t fit: pure batch data processing, scheduled jobs, simple cron tasks. Temporal’s strength is “complex state + long duration.” If your workload is “run a SQL export at 2 AM daily,” Temporal adds unnecessary overhead.
Pricing
Temporal offers an open-source version (MIT license) and Temporal Cloud (managed). Self-hosting requires deploying Temporal Server with Cassandra or PostgreSQL plus Elasticsearch, suitable for teams with dedicated ops capacity. Temporal Cloud bills per Action, with a free tier of 1M Actions/month and paid plans starting at $200/month.
Apache Airflow: The Industry Standard for Data Pipeline Scheduling
Airflow was born at Airbnb in 2014, became an Apache top-level project in 2019, and remains the most widely deployed scheduling tool in data engineering as of 2026. You’ll see “Airflow experience” on job postings far more often than any of the other three.
DAGs as Dependency Graphs
Airflow’s core concept is the DAG (Directed Acyclic Graph). You define a set of tasks and their dependency relationships. Airflow schedules execution in dependency order. Task A completes before Task B runs. Tasks C and D run in parallel. Task E waits for both C and D to finish.
This explicit dependency declaration maps naturally to data pipelines: extract from a database, clean and transform, load into the warehouse. Each step is an independent task with clear upstream and downstream relationships.
Programming Model
Airflow DAGs are defined in Python, but the execution model differs from a standard Python script. DAG files get parsed repeatedly (once per minute by default), so you cannot put heavy computation in the DAG definition itself. Actual task logic goes into Operators.
“`python
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime, timedelta
def extract_data():
# Pull data from source database
pass
def transform_data():
# Clean and transform
pass
def load_data():
# Load into data warehouse
pass
with DAG(
‘etl_pipeline’,
start_date=datetime(2026, 1, 1),
schedule_interval=’@daily’,
catchup=False,
) as dag:
extract = PythonOperator(
task_id=’extract’,
python_callable=extract_data,
)
transform = PythonOperator(
task_id=’transform’,
python_callable=transform_data,
)
load = PythonOperator(
task_id=’load’,
python_callable=load_data,
)
extract >> transform >> load
“`
The >> operator defines dependency order. extract finishes before transform runs, transform finishes before load starts.
Where Airflow Fits
Airflow is built for scheduled batch data workloads:
- ETL/ELT pipelines (daily syncs from production databases to the warehouse)
- Data quality checks (hourly validation runs)
- Report generation (weekly business reports)
- ML training pipelines (data prep, feature engineering, model training, evaluation)
Where it doesn’t fit: real-time stream processing, sub-second scheduling requirements, long-running business processes. Airflow’s task model assumes jobs start and finish within a bounded time window.
Pricing
Airflow is open source (Apache 2.0). Self-hosting requires PostgreSQL or MySQL, a message broker (Redis or RabbitMQ), and a chosen Executor (Celery or Kubernetes). Managed options include AWS MWAA (starting at $0.49/hour), Google Cloud Composer ($0.074/vCPU/hour), and Astronomer (from $100/month with enterprise support).
Prefect: Modern Data Flow Orchestration
Prefect’s founders found Airflow’s design outdated: repeated DAG parsing, all-or-nothing reruns on failure, a dated UI. They launched Prefect in 2018 with the goal of building a better developer experience for data orchestration.
Negative Engineering
Prefect’s design philosophy is “negative engineering,” meaning it avoids imposing unnecessary constraints. You don’t need a special DSL. You don’t need to understand DAG parsing mechanics. Write normal Python functions, mark them with @flow and @task decorators, and you’re done.
Programming Model
Prefect Flows and Tasks are plain Python functions. You can use if/else, for loops, try/except, and every other construct you already know.
“`python
from prefect import flow, task
@task
def extract_data():
# Pull data
return data
@task
def transform_data(data):
# Transform
return transformed
@task
def load_data(data):
# Load
pass
@flow
def etl_pipeline():
data = extract_data()
transformed = transform_data(data)
load_data(transformed)
if __name__ == “__main__”:
etl_pipeline()
“`
This code runs locally with python etl.py and also deploys to Prefect Server for scheduled execution. No special DAG parsing, no execution context to reason about.
Where Prefect Fits
Prefect targets similar workloads as Airflow but suits certain teams better:
- Workloads with dynamically generated tasks (task count depends on runtime data)
- Teams iterating quickly (Prefect’s local development loop is faster than Airflow’s)
- Organizations that prioritize observability (Prefect Cloud’s UI and monitoring are more polished)
- Python-first data teams (the API feels more natural than Airflow’s Operator pattern)
Where it doesn’t fit: same limitations as Airflow. Not designed for real-time streaming or long-running stateful business processes.
Pricing
Prefect 2.0 is open source (Apache 2.0) and can be self-hosted. Prefect Cloud offers a free tier (20,000 Task Runs/month), with paid plans starting at $250/month (Starter Plan) billed by Task Run volume.
Dagster: Data-Centric Orchestration
Dagster launched in 2019, founded by engineers with backgrounds at Facebook and Palantir data infrastructure teams. Their thesis: existing orchestration tools are task-centric, but data engineering should be data-centric. Tasks are the means; data assets are the end goal.
Software-Defined Assets
Dagster’s core concept is the Asset. An Asset can be a database table, a file, an ML model, or any data artifact. You define how to produce each Asset, and Dagster tracks dependency relationships, data lineage, and freshness automatically.
This declarative approach shifts your focus from “what tasks do I run” to “what data do I need.” Dagster derives the execution order from your asset definitions.
Programming Model
Dagster Assets use the @asset decorator. The function’s return value is the Asset content. Function parameters declare dependencies on upstream Assets.
“`python
from dagster import asset
@asset
def raw_orders():
# Read raw order data from source
return pd.read_sql(“SELECT * FROM orders”, conn)
@asset
def clean_orders(raw_orders):
# Clean data, depends on raw_orders
return raw_orders.dropna()
@asset
def order_metrics(clean_orders):
# Compute metrics, depends on clean_orders
return clean_orders.groupby(‘date’).agg({‘amount’: ‘sum’})
“`
These three Assets form a dependency chain: raw_orders → clean_orders → order_metrics. Dagster executes them in order and tracks each Asset’s freshness and lineage.
Where Dagster Fits
Dagster works best in data-intensive environments:
- Data warehouse modeling (dbt + Dagster is a popular combination)
- Feature engineering pipelines (ML feature tables with lineage)
- Data product development (BI dashboards, data APIs backed by managed tables)
- Organizations requiring data lineage for compliance, auditing, or impact analysis
Where it doesn’t fit: general business process orchestration. Dagster assumes your output is a data asset, not an order fulfillment or approval chain.
Pricing
Dagster is open source (Apache 2.0). Self-hosting requires Dagster Daemon + Dagit UI + PostgreSQL. Dagster Cloud offers a free tier (single user, limited compute), with the Pro Plan starting at $399/month billed by Compute Credits.
Head-to-Head Comparison
| Dimension | Temporal | Airflow | Prefect | Dagster |
|---|---|---|---|---|
| ,,,,,- | ,,,,, | ,,,,- | ,,,,- | ,,,,- |
| Core positioning | General-purpose workflow engine | Data pipeline scheduler | Modern data orchestration | Data-centric orchestration |
| Programming model | Native language functions, automatic state | DAG + Operators, declarative deps | Python functions + decorators | Asset dependency graph, declarative lineage |
| State management | Durable execution, auto-persisted, survives crashes | Task state in DB, rerun whole task on failure | Task state in server, supports partial reruns | Asset state + lineage unified, supports incremental updates |
| Learning curve | Medium (durable execution model) | Steep (DAG parsing, XCom, Executors) | Gentle (just Python) | Medium (Asset and lineage concepts) |
| Ops complexity | High (Server + Cassandra/PG + Elasticsearch) | High (Webserver + Scheduler + Executor + DB + broker) | Medium (Server + PostgreSQL) | Medium (Daemon + Dagit + PostgreSQL) |
Use Case Matrix
| Use Case | Temporal | Airflow | Prefect | Dagster |
|---|---|---|---|---|
| ,,,,, | ,,,,, | ,,,,- | ,,,,- | ,,,,- |
| Order fulfillment | ✅ Best fit | ❌ | ❌ | ❌ |
| Batch ETL | ⚠️ Overkill | ✅ Best fit | ✅ Best fit | ✅ Good fit |
| Real-time pipelines | ⚠️ Not designed for this | ❌ Not supported | ❌ Not supported | ⚠️ Possible, not ideal |
| ML training pipelines | ⚠️ Possible | ✅ Good fit | ✅ Good fit | ✅ Strong fit |
| Data warehouse modeling | ❌ | ✅ Good fit | ✅ Good fit | ✅ Best fit |
| Microservice orchestration | ✅ Best fit | ❌ | ❌ | ❌ |
Recommendations by Scenario
Your team runs daily ETL jobs
Pick Airflow or Prefect. Airflow has the largest ecosystem and the deepest talent pool. Prefect delivers a more modern developer experience with a cleaner UI. If you’re starting fresh in 2026, Prefect offers a smoother onboarding path. If your team already has Airflow expertise, switching carries migration cost without proportional benefit.
Skip Temporal (overkill for batch scheduling) and Dagster (steeper ramp-up for pure ETL).
You’re building a data warehouse and need lineage tracking
Pick Dagster. Its Asset model maps directly to warehouse tables and transformations. Paired with dbt, it provides unified management of data transformations and lineage in one tool.
Airflow can work here with an external lineage tool like OpenLineage, but the integration is bolted on rather than native. Prefect lacks comparable lineage features out of the box.
You’re orchestrating business processes with complex state
Pick Temporal. Order fulfillment, employee onboarding, cross-system approval workflows with human-in-the-loop steps: Temporal’s durable execution handles these natively. The other three tools were not designed for this category of problem.
You’re building ML training pipelines
Airflow, Prefect, and Dagster all work here. The deciding factor is your adjacent requirements:
- Already running Airflow? Stay with it.
- Prioritizing developer velocity? Go with Prefect.
- Need feature table management and lineage? Choose Dagster.
Temporal adds unnecessary complexity for batch ML workloads that don’t require durable execution semantics.
You need Saga-pattern microservice orchestration
Pick Temporal. Distributed transactions with compensation logic, cross-service coordination, and long-running stateful interactions are precisely what it was built for. None of the data-focused tools handle this well.
Making Your Decision
Choosing a workflow orchestration tool comes down to one question: what problem are you solving? Temporal solves reliable execution of complex business processes. Airflow and Prefect solve scheduled data task coordination. Dagster solves data lineage and asset observability.
The 2026 trend is clear: these tools are diverging rather than converging. Temporal isn’t coming for Airflow’s data engineering market. Dagster isn’t pivoting to general business process orchestration. Each tool has sharpened its focus.
If you’re still unsure, answer three questions:
- Are your workloads scheduled batch jobs, or long-running stateful processes?
- Do you need data lineage tracking as a first-class feature?
- How much operational capacity does your team have for self-hosting?
Those answers will point you to the right tool.
Stay updated with our latest AI insights