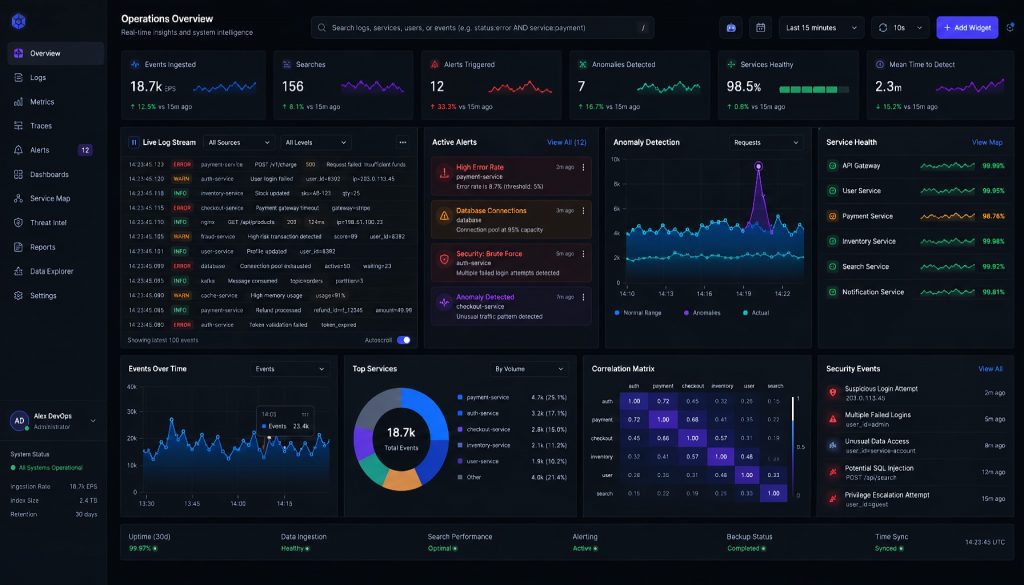
凌晨两点四十七分,手机震动。PagerDuty 推了一条 P1,某核心微服务的错误率飙到 12%。你揉着眼睛打开笔记本,登进 Splunk Cloud,输入查询语句,等了八秒才出结果。问题定位花了二十分钟,修复又花了十分钟。回到床上已经三点半。
第二天早上,你打开 Splunk 的用量面板,发现这个月的日志摄入量已经超出合约额度 35%。超出部分按需计费,账单预估多了两万多块。而那个凌晨的 P1?追根溯源是一个下游依赖超时,日志本身只有几百条有价值,剩下的全是 debug 噪音。你花钱存了一堆噪音,然后花钱查了一堆噪音。
这个场景,对很多运维团队来说并不陌生。
Splunk 的定价为什么让人想跑
Splunk 是日志管理领域的老大哥,这点没人否认。SPL 查询语言强大,仪表盘成熟,生态丰富。但它的商业模式有一个根本性的问题:按日志摄入量(ingestion volume)收费。
这个计费逻辑在 2010 年代初期是合理的,那时候大多数公司每天产生的日志可能就几十 GB。但到了 2026 年,一个中等规模的 Kubernetes 集群,跑着几百个 Pod,每天轻松产出几百 GB 甚至 TB 级别的日志。Splunk 的 per-GB 定价意味着你的基础设施越健康地增长,你付的钱就越多。
更要命的是,Splunk 的定价不透明。企业版的报价需要走销售,不同客户拿到的折扣差异很大。很多团队签约时觉得还行,半年后业务增长,日志量翻倍,账单就炸了。2023 年 Cisco 收购 Splunk 之后,定价策略并没有变得更友好,反而让一些客户担心未来会更贵。
于是,越来越多的 SRE 和 CTO 开始认真评估 Splunk 替代品。不是因为 Splunk 不好用,而是因为用不起。
SigNoz:OpenTelemetry 原生的开源日志管理工具
假设你是一个 30 人的云原生团队,技术栈全是 Go 和 Kubernetes,刚把 tracing 接入了 OpenTelemetry。你想要一个工具,能同时看 logs、metrics、traces,而且不想被供应商锁定。
SigNoz 就是为这个场景设计的。
它是一个完全开源(Apache 2.0)的可观测性平台,底层用 ClickHouse 做存储。Logs、metrics、traces 三个信号在同一个界面里关联查看,不需要在三个不同产品之间跳转。对于已经在用 OpenTelemetry SDK 和 Collector 的团队来说,接入 SigNoz 几乎是零摩擦,因为它本身就是围绕 OTel 协议设计的。
SigNoz 的查询性能相当不错。ClickHouse 本身是列式存储,对日志这种高基数、大体量的数据类型有天然优势。在社区的基准测试中,SigNoz 处理同等数据量的查询速度通常优于 Elasticsearch。
自托管版本完全免费,没有功能阉割。SigNoz 也提供云托管版本,定价按数据量阶梯计费,起步价比 Splunk 低得多。对于日均 50GB 日志的团队,SigNoz Cloud 的月费大约是 Splunk 的五分之一到四分之一。
不过 SigNoz 也有短板。它的社区虽然活跃,但相比 Elastic 或 Grafana 的生态还是年轻。如果你需要大量现成的集成(比如几百种数据源的 parser),SigNoz 目前的覆盖面不如老牌选手。另外,自托管 ClickHouse 集群本身需要一定的运维能力,小团队可能更适合直接用云版本。
Elastic Stack:灵活强大但运维成本不低
你大概率已经用过 Elasticsearch。很多团队的第一个日志系统就是 ELK(Elasticsearch + Logstash + Kibana)。它是 Splunk 最早的替代品,也是目前市场份额最大的开源日志方案。
Elastic 的核心优势在于搜索。全文检索是它的基因,复杂的日志查询、聚合分析、模式识别,Elastic 都能做得很好。Kibana 的可视化能力也很成熟,Dashboard 和告警规则可以做得很精细。
但 ELK 的问题在于运维复杂度。
一个生产级的 Elasticsearch 集群,需要合理规划分片策略、索引生命周期、JVM 堆内存、磁盘水位线。集群规模一大,split brain、shard rebalancing、mapping explosion 这些问题会陆续出现。很多团队最终发现,他们花在运维 ELK 上的工程师时间,折算成本并不比 Splunk 的账单便宜多少。
Elastic 公司这几年也在推自家的云服务(Elastic Cloud),试图解决自托管的运维痛点。云版本确实省心,但定价同样不便宜,特别是当你需要跨区域部署或者长期保留日志的时候。
还有一个值得关注的变化:Elastic 在 2024 年把许可证从 SSPL 改回了 AGPL。这对自托管用户来说是个好消息,意味着社区版可以更自由地使用。但 AGPL 仍然有传染性,如果你的产品是 SaaS 并且直接暴露了 Elasticsearch 的功能,需要注意合规风险。
适合什么团队?有专职平台工程师、日志查询需求复杂、需要全文检索能力的中大型团队。如果你只有两三个 SRE,不想把精力花在维护 ES 集群上,可能要考虑其他选项。
Grafana Loki:为 Kubernetes 而生的轻量级日志系统
有一类团队的需求很明确:他们已经在用 Grafana 看 metrics(通过 Prometheus),现在想把日志也接进来,在同一个 Grafana 界面里关联查看。预算有限,日志量不小,但大多数时候只需要按标签过滤再看具体内容,不需要全文索引。
Grafana Loki 就是为这个场景量身定制的。
Loki 的设计哲学很独特:它不索引日志内容,只索引元数据标签(labels)。这意味着存储成本极低,日志正文被压缩后直接存到对象存储(S3、GCS、MinIO),只有标签会被索引。对于 Kubernetes 环境来说,Pod 名、namespace、container 名这些标签天然就有,不需要额外配置。
实际效果是什么?同样 100GB/天的日志量,Loki 的存储成本可能只有 Elasticsearch 的十分之一。因为 S3 的存储单价远低于 SSD 块存储,而 Loki 不需要为每一行日志建倒排索引。
当然,这个设计也有代价。如果你想搜索日志内容中的某个关键词,Loki 需要扫描所有匹配标签范围内的日志块,速度不如 Elasticsearch。对于”我要在过去 7 天所有服务的日志里搜一个错误 ID”这种查询,Loki 会比较慢。但如果你的使用模式是”先按 service + 时间范围缩小范围,再看具体日志”,Loki 完全够用。
Loki 在 Kubernetes 生态里的部署体验非常好。配合 Promtail 或 Grafana Alloy(新一代采集器),Helm chart 一键部署,几分钟就能开始收日志。而且 Grafana Labs 提供了 Grafana Cloud 的托管版 Loki,免费套餐每月有 50GB 的日志额度,对小团队来说足够起步。
Better Stack:现代 SaaS 体验和开发者友好的日志管理
你可能没听过 Better Stack,但你大概率听过 Logtail。Better Stack 是 Logtail 的母公司,2022 年品牌合并后,把 uptime monitoring、incident management 和日志管理整合成了一个平台。
Better Stack 的卖点是体验。
打开它的日志界面,你会觉得这是一个 2026 年该有的产品:查询响应快、UI 干净、Live Tail 实时流畅、SQL 式查询语法上手成本低。它没有 Kibana 那种”功能多到需要培训才能用”的感觉,也没有 Splunk 那种”企业级但笨重”的氛围。
定价方面,Better Stack 按摄入量计费,但起步价很低。免费套餐每月 1GB,付费版从每月 $29 起,包含 30 天保留。相比 Splunk 动辄数万美元的年费,这对中小团队来说友好得多。
Better Stack 的 S3 归档功能也值得一提。超过保留期的日志可以自动归档到你自己的 S3 桶里,需要的时候再 rehydrate 回来查询。这解决了”日志保留要求长但平时不会查”的合规需求。
不过,Better Stack 目前没有开源版本,数据完全托管在它的基础设施上。对于有数据本地化要求的中国企业来说,这可能是个障碍。另外,它在复杂聚合分析和自定义 parser 方面的能力不如 Elastic 或 Splunk 那么深。
适合谁?20 人以下的开发团队、希望快速启用日志管理但不想花精力运维的初创公司、已经在用 Better Stack 做 uptime 监控的团队。
Axiom:数据湖架构,为长期存储而生
有些场景下,你不只是想看最近几天的日志。金融行业要求日志保留 7 年,医疗行业可能更长。这种时候,传统日志系统的”热存储”模式就很贵,你不可能把 7 年的日志都放在 Elasticsearch 的 SSD 上。
Axiom 用了一个不同的思路:它把日志当作数据湖来管理。所有数据摄入后立刻被压缩、分区、存到对象存储。查询时通过自研的列式查询引擎直接扫描对象存储,不需要预先建索引。
这意味着 Axiom 的存储成本非常低,特别是长期保留场景。同样存 1TB 日志一年,Axiom 的费用可能只有 Splunk 的十分之一。而且数据进来就能查,不需要定义 schema 或者提前设计索引模式。
Axiom 的查询语言叫 APL(Axiom Processing Language),语法接近 KQL(Kusto Query Language),如果你用过 Azure Data Explorer 会很熟悉。查询速度在大时间范围内表现不错,因为列式存储天然适合这种”扫描大量数据、聚合少量字段”的模式。
但 Axiom 的实时性不如专门做日志搜索的工具。从日志摄入到可查询,通常有几秒到十几秒的延迟。如果你的场景是”出了故障立刻要看最新日志”,这个延迟可能不太舒服。另外,Axiom 目前是纯 SaaS,没有自托管选项。
适合什么场景?合规驱动的日志保留(金融、医疗、政务)、大体量日志的长期分析(安全审计、用户行为回溯)、不需要毫秒级实时查询的团队。
核心对比:五个 Splunk 替代品怎么选
说了这么多,把关键信息放到一张表里对比:
| 维度 | SigNoz | Elastic Stack | Grafana Loki | Better Stack | Axiom |
|---|---|---|---|---|---|
| 开源/商业 | 开源 (Apache 2.0) | 开源 (AGPL) + 商业 | 开源 (AGPL) + 商业 | 纯商业 SaaS | 纯商业 SaaS |
| 部署模式 | 自托管 / 云托管 | 自托管 / 云托管 | 自托管 / 云托管 | 纯 SaaS | 纯 SaaS |
| 定价起点 | 自托管免费;云版 $199/月 | 自托管免费;Cloud $95/月起 | 自托管免费;Cloud 免费 50GB/月 | 免费 1GB/月;$29/月起 | 免费 500MB/月;$25/月起 |
| 默认日志保留 | 自定义(取决于磁盘) | 自定义(ILM 管理) | 自定义(对象存储无上限) | 30 天(付费可延长) | 30 天(企业版可定制) |
| 全文检索 | 支持 | 强项 | 不支持(仅标签索引) | 支持 | 支持 |
| 最适场景 | OTel 原生团队、logs+traces 关联 | 复杂查询、安全分析 | K8s 环境、低成本大体量 | 快速启用、开发者体验 | 合规长期存储、大体量归档 |
这张表给你一个快速参考,但选型不应该只看参数。下面按团队情况给一些更具体的建议。
按团队规模和场景选日志管理平台
5-20 人的初创团队,预算紧张:Better Stack 或 Grafana Loki(Cloud 版)。前者零运维直接用,后者有免费额度且和 Grafana 生态无缝衔接。这个阶段不要花时间运维基础设施,把精力放在产品上。
20-100 人的成长期团队,已有 Kubernetes 和 Prometheus:Grafana Loki + SigNoz 是两个好选项。如果你已经在用 Grafana 看 metrics,Loki 是最自然的扩展。如果你想要 logs+traces 一体化体验,SigNoz 更合适。两者都可以自托管控制成本。
100+ 人的中大型团队,有平台工程组:Elastic 重新回到考虑范围。你有人力运维集群,也需要 Elastic 的高级功能(安全分析、异常检测、机器学习)。但如果主要需求是日志查看和告警,Elastic 可能过重了。
有合规要求、需要长期保留日志的企业:Axiom 是专门为这个场景设计的。数据湖架构让长期存储成本可控,查询引擎对大时间范围的扫描做了优化。如果数据不能出境,需要评估 Axiom 的数据中心位置是否满足要求。
已经 all-in OpenTelemetry 的团队:SigNoz 是当前最贴合 OTel 原生体验的选择。它对 OTel Collector 的日志接入做了专门优化,trace-log 关联在同一界面完成,不需要跳转。
从 Splunk 迁移的现实考量
最后聊一个很多人关心但不太敢说的话题:迁移的阵痛。
Splunk 用久了,团队会积累大量 SPL 查询、自定义 Dashboard、告警规则。这些东西不是换个工具就能一键迁移的。每个替代品的查询语言都不一样,Kibana 的 Dashboard 和 Grafana 的 Dashboard 逻辑也不同。
比较务实的做法是渐进迁移。先把新产生的日志双写到新平台,跑一两周看查询体验和性能是否满足需求。老数据留在 Splunk 里直到过期。关键的告警规则在新平台上重建并验证。等团队熟悉新工具后,再逐步关闭 Splunk 的摄入。
这个过程通常需要一到三个月,取决于你在 Splunk 上积累了多少自定义逻辑。但好消息是,大多数团队迁移完成后,日志相关的基础设施成本会降低 50% 到 80%。
没有完美的日志工具。Splunk 贵但确实好用,开源方案便宜但需要投入运维精力,SaaS 方案省心但数据在别人手里。选择哪个,取决于你的团队现在最缺什么:是钱、是人、还是时间。想清楚这个问题,答案自然就明确了。
Stay updated with our latest AI insights