A data engineer stared at error logs on his screen, manually restarting a failed ETL job for the third time. “Why did step 47 hang again?” he asked his colleague. “Last time it was step 23. Now it failed somewhere else.” His colleague didn’t look up. “Because we don’t have workflow orchestration. Everything runs on chained scripts.”
This was daily life for many data teams in the early 2020s. When jobs failed, nobody knew where to restart. State scattered across different log files. One broken link stopped the entire pipeline. Workflow orchestration tools emerged to fix these problems: manage complex multi-step processes, handle automatic retries, track state, manage dependencies, and recover from failures.
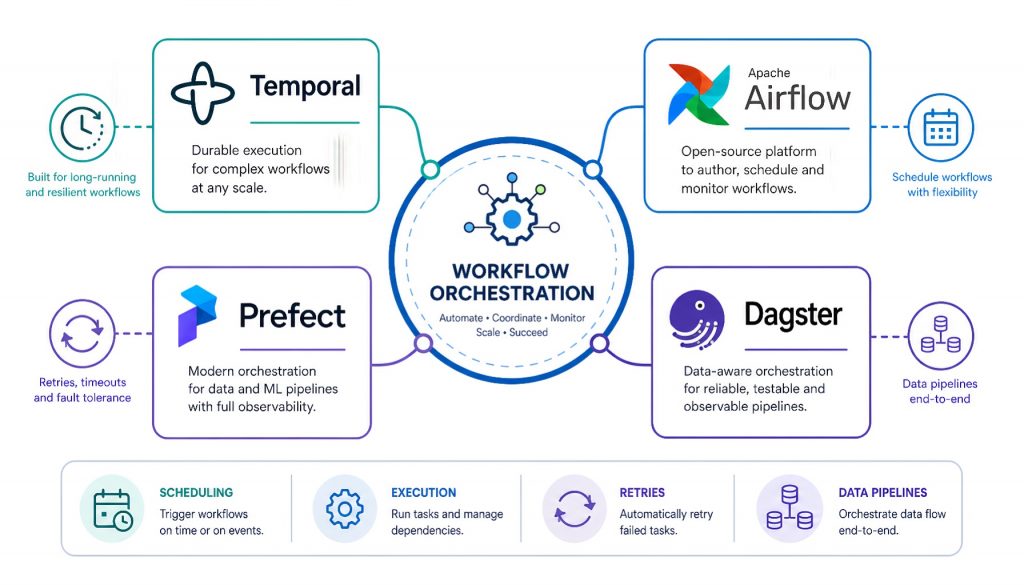
By 2026, the field has clear divisions. Apache Airflow is the veteran data pipeline scheduler. Its Python DAG pattern became an industry standard. Prefect and Dagster are next-generation data orchestration tools, targeting Airflow but with better developer experience. Temporal took a completely different path. It’s not a “data pipeline tool” but a general-purpose distributed workflow engine for any long-running process that needs reliable execution.
These four tools often get compared, but they actually solve problems at different levels. Pick the wrong one and you’ll either use a sledgehammer to crack a nut or bring a butter knife to chop down a tree. This article breaks them down across four dimensions: positioning, programming model, state management, and use cases. You’ll find the one that actually fits your team.
Temporal: General Workflow Engine Beyond Data Pipelines
Temporal’s founding team came from Uber’s Cadence project. Their problem wasn’t “schedule data tasks” but “how to make complex processes in distributed systems execute reliably.” Payment flows, user registration, cross-service approval processes are what Temporal targets.
Core Philosophy: Durable Execution
The most distinctive feature of Temporal is durable execution. Your workflow code looks like ordinary function calls, but every step’s state gets persisted during execution. Process crashed? It restarts from where it left off. API call timed out? Automatic retry. Dependent service down? Wait for recovery and continue.
This “write like synchronous code, run like a distributed system” experience is Temporal’s core selling point. You don’t manage state machines yourself or write complex error recovery logic. Temporal’s execution engine handles all of it.
Programming Model
Temporal workflows use ordinary programming languages (Go, Java, Python, TypeScript, .NET), no special DSL required. A workflow is just a function that can call Activities (units that execute actual tasks), start child workflows, or wait for external signals.
“`python
@workflow.defn
class OrderWorkflow:
@workflow.run
async def run(self, order_id: str) -> str:
# Step 1: Check inventory
await workflow.execute_activity(
check_inventory,
order_id,
start_to_close_timeout=timedelta(seconds=30),
)
# Step 2: Charge payment
payment_result = await workflow.execute_activity(
charge_payment,
order_id,
start_to_close_timeout=timedelta(minutes=5),
)
# Step 3: Ship order
await workflow.execute_activity(
ship_order,
order_id,
start_to_close_timeout=timedelta(hours=1),
)
return “Order completed”
“`
This code looks like three sequential steps, but Temporal guarantees: any failed step retries automatically, process restarts don’t affect execution, each step has independent timeout management. You don’t write any state management code.
Use Cases
Temporal fits best for “long-running, complex state, high reliability” business processes. Typical examples:
- Order fulfillment (order → payment → shipping → delivery → signature, each step might span hours to days)
- User onboarding (submit application → approval → background check → contract signing, with human approval steps)
- Cross-system data sync (read from system A → transform → write to system B → verify consistency)
- Microservice orchestration (Saga pattern distributed transactions with compensation mechanisms)
Not suitable for: pure batch data processing, scheduled tasks, simple cron jobs. Temporal’s strength is “complex state + long-running.” If your task is “run a SQL export every night at midnight,” using Temporal is overkill.
Pricing and Deployment
Temporal has an open-source version (MIT license) and managed cloud service (Temporal Cloud). The open-source version requires deploying Temporal Server (depends on Cassandra/PostgreSQL + Elasticsearch), suitable for teams with ops capacity. Temporal Cloud bills by Actions executed, with a free tier of 1 million Actions per month, paid plans starting at $200/month.
Apache Airflow: De Facto Standard for Data Pipeline Scheduling
Airflow was born at Airbnb in 2010 and became an Apache top-level project in 2016. By 2026, it remains the most widely used scheduling tool in data engineering. You see “familiar with Airflow” in job descriptions far more often than the other three tools.
Core Philosophy: DAG as Task Dependency Graph
Airflow’s core concept is the DAG (Directed Acyclic Graph). You define a set of tasks and their dependencies. Airflow handles scheduling in dependency order. Task A completes before task B executes. Tasks C and D can run in parallel. Task E waits for both C and D to finish.
This “explicitly declare dependency relationships” design fits data pipelines perfectly: first extract data from databases, then clean and transform, finally load into the data warehouse. Each step is an independent task with clear dependencies.
Programming Model
Airflow DAGs are defined in Python, but its execution model differs from ordinary Python programs. DAG files get parsed repeatedly (once per minute), so you can’t do heavy computation in DAG files. Actual task logic goes into Operators.
“`python
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime, timedelta
def extract_data():
# Extract data from database
pass
def transform_data():
# Clean and transform data
pass
def load_data():
# Load to data warehouse
pass
with DAG(
‘etl_pipeline’,
start_date=datetime(2026, 1, 1),
schedule_interval=’@daily’,
catchup=False,
) as dag:
extract = PythonOperator(
task_id=’extract’,
python_callable=extract_data,
)
transform = PythonOperator(
task_id=’transform’,
python_callable=transform_data,
)
load = PythonOperator(
task_id=’load’,
python_callable=load_data,
)
extract >> transform >> load # Define dependencies
“`
This DAG defines execution order for three tasks. The >> operator represents dependencies: extract completes before transform executes, transform completes before load executes.
Use Cases
Airflow fits best for scheduled batch data processing. Typical scenarios:
- ETL/ELT data pipelines (daily sync from operational databases to data warehouse)
- Data quality checks (hourly data validation)
- Report generation (weekly business reports)
- Machine learning training pipelines (data prep → feature engineering → model training → model evaluation)
Not suitable for: real-time stream processing (Airflow is not a stream engine), tasks needing sub-second scheduling, long-running business processes (Airflow tasks assume “run and finish”).
Pricing and Deployment
Airflow is open-source and free (Apache 2.0 license). You can self-host (requires PostgreSQL/MySQL + Redis/RabbitMQ + Celery/Kubernetes Executor) or use managed services. Managed options include:
- AWS MWAA (Amazon Managed Workflows for Apache Airflow): from $0.49/hour
- Google Cloud Composer: from $0.074/vCPU/hour
- Astronomer: from $100/month (managed Airflow + enterprise support)
Prefect: Modern Data Flow Orchestration
Prefect’s founding team thought Airflow’s design was too old: DAG files repeatedly parsed, failed tasks require re-running entire DAGs, UI not modern enough. They founded Prefect in 2018 with the goal of “building a better Airflow.”
Core Philosophy: Negative Engineering
Prefect’s design philosophy is called “negative engineering”: don’t impose constraints, let users write code the way they know. You don’t need to learn a special DSL or understand Airflow’s DAG parsing mechanism. Just write ordinary Python functions, mark them with @flow and @task decorators.
Programming Model
Prefect’s Flows and Tasks are ordinary Python functions. You can use if/else, for loops, try/except. Writing them feels no different from regular scripts.
“`python
from prefect import flow, task
@task
def extract_data():
# Extract data
return data
@task
def transform_data(data):
# Transform data
return transformed
@task
def load_data(data):
# Load data
pass
@flow
def etl_pipeline():
data = extract_data()
transformed = transform_data(data)
load_data(transformed)
if __name__ == “__main__”:
etl_pipeline()
“`
This code can run directly (python etl.py) or deploy to Prefect Server for scheduled execution. No special DAG parsing required, no execution context to understand.
Use Cases
Prefect’s positioning is close to Airflow, but better suited for:
- Scenarios requiring dynamic task generation (task count not fixed, depends on runtime data)
- Teams with frequent development iterations (Prefect’s local dev experience beats Airflow)
- Teams valuing observability (Prefect Cloud’s UI and monitoring are far more modern than Airflow)
- Python-centric data teams (Prefect’s Python API feels more natural)
Not suitable for: similar to Airflow, not for real-time stream processing or long-running business processes.
Pricing and Deployment
Prefect 2.0 is open-source (Apache 2.0), you can self-host Prefect Server. Prefect Cloud is the managed version, with a free tier (20,000 Task Runs per month), paid plans starting at $250/month (Starter Plan), billed by Task Run count.
Dagster: Data-Centric Orchestration Tool
Dagster went open-source in 2019. The founder previously built data infrastructure at Facebook and Palantir. Their view: existing orchestration tools are “task-centric,” but data engineering should be “data-centric.” Tasks are means, data is the goal.
Core Philosophy: Software-Defined Assets
Dagster’s core concept is the Asset. An Asset can be a data table, a file, an ML model. You define “how to generate this Asset.” Dagster handles tracking dependencies between Assets, data lineage, and update times.
This “declarative” design lets you focus on “what data I need” instead of “what tasks to execute.” Dagster automatically infers execution order.
Programming Model
Dagster Assets are defined with the @asset decorator. Function return values are the Asset contents. Function parameters declare upstream Asset dependencies.
“`python
from dagster import asset
@asset
def raw_orders():
# Read raw order data from database
return pd.read_sql(“SELECT * FROM orders”, conn)
@asset
def clean_orders(raw_orders):
# Clean data, depends on raw_orders
return raw_orders.dropna()
@asset
def order_metrics(clean_orders):
# Calculate metrics, depends on clean_orders
return clean_orders.groupby(‘date’).agg({‘amount’: ‘sum’})
“`
These three Assets form a dependency chain: raw_orders → clean_orders → order_metrics. Dagster automatically executes in order and tracks each Asset’s update time and data lineage.
Use Cases
Dagster fits best for “data-intensive” scenarios, especially:
- Data warehouse modeling (DBT + Dagster is a common combination)
- Feature engineering pipelines (feature tables for ML training)
- Data product development (data tables for BI dashboards, data APIs)
- Organizations needing data lineage tracking (compliance, auditing, impact analysis)
Not suitable for: general business process orchestration (Dagster’s design assumes “generating data assets,” not order flows or approval processes).
Pricing and Deployment
Dagster is open-source (Apache 2.0). You can self-host Dagster Daemon + Dagit UI. Dagster Cloud is the managed version, with a free tier (single user, limited resources), paid plans starting at $399/month (Pro Plan), billed by Compute Credits.
Comparison Dimensions: Which Fits You?
1. Core Positioning
- Temporal: General workflow engine for business process orchestration
- Airflow: Data pipeline scheduling tool for batch ETL
- Prefect: Modern data flow orchestration, improved Airflow
- Dagster: Data-centric orchestration emphasizing data lineage and observability
2. Programming Model
- Temporal: Ordinary function calls, automatic state management
- Airflow: DAG + Operators, declarative dependencies
- Prefect: Ordinary Python functions + decorators
- Dagster: Asset dependency graph, declarative data lineage
3. State Management
- Temporal: Durable execution, automatic state persistence, process restarts don’t affect execution
- Airflow: Task state stored in database, failures require manual or automatic re-run of entire task
- Prefect: Task state stored in Prefect Server, supports partial re-runs
- Dagster: Asset state and data lineage unified management, supports incremental updates
4. Use Case Fit
| Scenario | Temporal | Airflow | Prefect | Dagster |
|---|---|---|---|---|
| Order fulfillment | ✅ Best fit | ❌ Not suitable | ❌ Not suitable | ❌ Not suitable |
| Batch ETL | ⚠️ Works but overkill | ✅ Best fit | ✅ Best fit | ✅ Suitable |
| Real-time pipelines | ⚠️ Not designed for this | ❌ Not supported | ❌ Not supported | ⚠️ Works but not optimal |
| ML training pipeline | ⚠️ Works | ✅ Suitable | ✅ Suitable | ✅ Very suitable |
| Data warehouse modeling | ❌ Not suitable | ✅ Suitable | ✅ Suitable | ✅ Best fit |
| Microservice orchestration | ✅ Best fit | ❌ Not suitable | ❌ Not suitable | ❌ Not suitable |
5. Learning Curve
- Temporal: Moderate. Few core concepts, but you need to understand the durable execution model
- Airflow: Steep. DAG parsing mechanism, execution context, XCom, differences between Executors
- Prefect: Gentle. If you know Python, almost no additional learning required
- Dagster: Moderate. Asset and data lineage concepts need understanding, but design is intuitive
6. Operational Complexity
- Temporal: High. Requires deploying Temporal Server, Cassandra/PostgreSQL, Elasticsearch
- Airflow: High. Requires deploying Webserver, Scheduler, Executor, database, message queue
- Prefect: Medium. Requires deploying Prefect Server/Orion + PostgreSQL, simpler than Airflow
- Dagster: Medium. Requires deploying Dagster Daemon + Dagit + PostgreSQL
Selection Guide: Match Tools to Scenarios
You’re doing data engineering, running ETL jobs daily
First choice: Airflow or Prefect. Airflow is the industry standard with mature ecosystem and easy hiring. Prefect is the modern choice with better developer experience and friendlier UI. If your team is starting fresh in 2026, go with Prefect. If you already have Airflow experience, staying with Airflow works fine.
Not recommended: Temporal (overkill) or Dagster (steeper learning curve).
You’re building a data warehouse and need data lineage tracking
First choice: Dagster. Its Asset model naturally fits data warehouse scenarios. Combined with DBT, you can unify data transformation and data lineage management.
Second choice: Airflow + external data lineage tools (like OpenLineage). Prefect doesn’t match Dagster’s native data lineage capabilities.
You’re orchestrating business processes with complex state and long-running execution
Only Temporal recommended. Order fulfillment, user onboarding, cross-system approval flows require Temporal’s durable execution. The other three tools weren’t designed for this.
You’re building ML training pipelines
Airflow, Prefect, and Dagster all work. Which one depends on your other needs:
- If your team already uses Airflow, keep using it
- If you value developer experience, choose Prefect
- If you need feature table management and lineage tracking, choose Dagster
Temporal isn’t suitable because ML training is typically batch processing that doesn’t need durable execution.
You’re orchestrating microservices and need Saga patterns
Only Temporal recommended. Distributed transactions, compensation mechanisms, cross-service orchestration are what Temporal was designed for. The other three tools don’t fit.
Final Thoughts
Choosing a workflow orchestration tool fundamentally answers “what problem am I solving?” Temporal solves “reliable execution of complex business processes.” Airflow/Prefect solve “scheduled execution of data tasks.” Dagster solves “data lineage and observability.”
The 2026 trend shows these tools have increasingly clear boundaries. Temporal won’t chase Airflow’s data engineering market. Dagster won’t do general business process orchestration. Pick the right tool and your development efficiency doubles. Pick the wrong one and you fight the framework daily.
If you’re still unsure, ask yourself three questions:
- Are my tasks scheduled batch processing or long-running processes?
- Do I need data lineage tracking?
- How much operational capacity does my team have?
The answers will point to the right choice.
Stay updated with our latest AI insights